The importance of the optimal
column order described in this note was excerpted from a book
"Troubleshooting Oracle Performance" by Christian Antognini.
One of the principles you have to keep in mind when you design a table is that you have to put those columns frequently selected in the first place.
In Oracle, a row stored in a database block has the following format:
Row Header + L1+D1+L2+D2+L3+D3+ ..... +Ln + Dn
Ln = length of column n
Dn = Data of column n
The
essential thing to understand in this format is that the database
engine does not know the offset (or staring point) of the columns in a
row. For example, if it has to locate column 5, it has to start by
locating column 1. Then, based on the length of column 1, it locates
column 2. In the same way based on the length of column 4, it locates
column 5. So whenever a row has more than a few columns, a column near the beginning of the row might be located much faster than a column near the end of the row. I did some googling to find the PostgreSQL row format, but I failed to find it.
Instead
I have decided to do the test to check if the query referencing the
first column performs faster than the query referencing the last column.
I
have created a broad table with 150 columns. I am frequently confronted
with a table with over 100 columns in a production system, which is not
good modelling.
SELECT 'CREATE TABLE test ('
||string_agg('t_'||i
||' varchar(10) default ''k'' ',', ')
||' )'
FROM generate_series(1,150) AS a(i);
When you execute the above query, you get the following script:
CREATE TABLE test (
c_1 varchar(10) default 'k'
, c_2 varchar(10) default 'k'
, c_3 varchar(10) default 'k'
......
, c_149 varchar(10) default 'k' ,
c_150 varchar(10) default 'k' );
Let's load some data into the table.
INSERT INTO test
SELECT 'AB' FROM GENERATE_SERIES(1,1000000);
SELECT * FROM test LIMIT 10;
VACUUM test;
SELECT PG_RELATION_SIZE('test');
Note
that the table has default values so we can be sure that all columns
contain something. The table I have just created is about 341 MB in
size.
Let's do a count(*) and see how long it takes:
SELECT COUNT(*) FROM test; --60.93 ms
Let's compare this to a count on the first column.
SELECT COUNT(C_1) FROM test; --95.78 ms
We
can see a small difference in performance. It seems that count(*) has
to check for the existence of the row while count(C_1) has to check if a
NULL value is fed to the aggregate or not. In case of NULL the value
has to be ignored.
Now Let's see what happens if we access the 100th column. The time to do that differ significantly:
SELECT COUNT(C_100) FROM test; --400 ms
The elapsed time has basically quadrupled. The performance is even worse if we do a count on the last column:
SELECT COUNT(C_150) FROM test; --600 ms
Actually
I fell off my chair after seeing the test result because I had not
expected big difference. It is important to note that the query
referencing the first column peforms about 6 (600/95) times faster than
the query referencing the 150th column. I guess the PostgreSQL engine
optimizes every access and thus avoids locating and reading columns
that are not necessary for the processing. For example, the query
SELECT COUNT(C_100) FROM test stops walking the row when the 100th
column is located. SELECT COUNT(*) FROM test performs best because it
does not have to check if a NULL vlaue is fed to the aggregate. We can
infer that when tables have many columns and SQL statements frequently
reference very few of the columns located at the end of the row, the overhead related to the position of the columns is noticeable.
Conclusion
When you design a table, place intensively accessed columns first.
Be careful about making your tables too wide because you may run into
performance issues. From a performance point of view, you should be
careful to access only the columns that are really needed.
Addendum
In
a recent data modelling project I worked on one of the modeling
principles the data architect set up was to remove one to one entity
relationship, which I think was a preposterous principle. The DA
insisted that the one to one relationship could indicate that two
entities actually belonged in the same entity. It is true that a one to
one relationship should be rare in any relational database design. Very
few one to one relationships exist in real life. However, there are use
cases where the one to one relatioinship is necessary for database
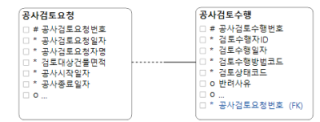
performance. Let's consider the following entity relationship diagram:
![]()

Logically
two sample entities in the above diagram can be merged into one. But if
the two entities have too many attributes (Let's say over 100
attributes), it would be a good idea not to integrate them. If we integrate them and access those columns near the end of the row, we may run into performance degradation.